Our network guys observed a big traffic between our SharePoint server and its content database. We then did some tests and found a SPQuery for 1000 list items resulting in more than 3000+ rows returned from content database, and each row has more than 120 columns.
Why database returns more rows than the list item number? Is it returning all versions? It would be nightmare if that's case because the versions will keep growing in product environment. Good news is that SPQuery is only getting latest version, not all versions from database. The extra rows actually are related to Multi-lookup values.
To explore this let's first create a simple Province custom list:
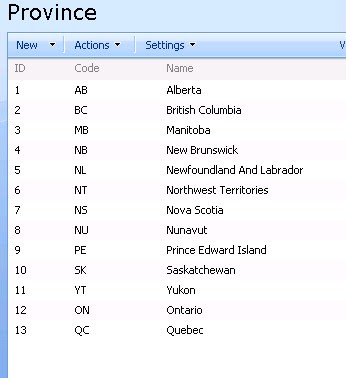
Next we create a multi-lookup site column named "AvailableProvinces" referencing the Province list:
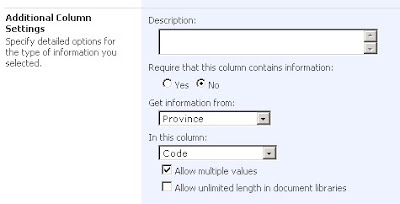
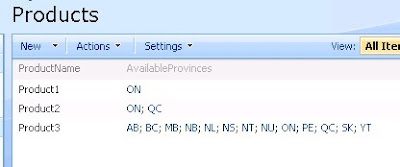
Then we create another custom list to use this "AvailableProvinces" column, and add three list itmes:
Now we can build a simple console application to test the SPQuery:
using System;
using System.Text;
using Microsoft.SharePoint;
class Test
{
static void Main()
{
QueryData("http://localhost", "Products", "Product1");
QueryData("http://localhost", "Products", "Product2");
QueryData("http://localhost", "Products", "Product3");
Console.Read();
}
static void QueryData(string siteName, string listName, string productName)
{
using (SPSite site = new SPSite(siteName))
{
using (SPWeb web = site.OpenWeb())
{
SPList list = web.Lists[listName];
SPQuery query = new SPQuery();
query.ViewFields = "<FieldRef Name='ProductName' />";
query.ViewFields += "<FieldRef Name='AvailableProvinces' />";
StringBuilder queryText = new StringBuilder();
queryText.Append("<Where><Eq><FieldRef Name=\"ProductName\"/><Value Type=\"Text\">");
queryText.Append(productName);
queryText.Append("</Value></Eq></Where>");
query.Query = queryText.ToString();
SPListItemCollection items = list.GetItems(query);
Console.WriteLine("Item count: {0}", items.Count);
}
}
}
}
Start the SQL Server profile and you will notice complicate SQL queries sent to content database. The SQL for the first SPQuery (product1) is:
exec sp_executesql N' SELECT t5.*, t7.[MetaInfo] FROM (SELECT DISTINCT t3.*, t4.[tp_Ordinal] , t2.[tp_ID] AS c4, t8.[nvarchar3] AS c4c5 FROM ( SELECT TOP 2147483648 t1.[Type] AS c0,t1.[Id] AS
c2,UserData.[tp_DeleteTransactionId],UserData.[nvarchar3],UserData.[tp_ID],UserData.[tp_CopySource],UserData.[tp_Version],UserData.[tp_IsCurrentVersion],UserData.[tp_Created],CASE
WHEN DATALENGTH(t1.DirName) = 0 THEN t1.LeafName WHEN DATALENGTH(t1.LeafName) = 0 THEN t1.DirName ELSE t1.DirName + N''/'' + t1.LeafName END AS
c1,UserData.[tp_HasCopyDestinations],UserData.[tp_ModerationStatus],UserData.[tp_Level],UserData.[tp_SiteId],UserData.[tp_LeafName],UserData.[tp_CalculatedVersion],UserData.[tp_DirName],t1.[ScopeId]
AS c3,UserData.[int1] FROM UserData LEFT OUTER LOOP JOIN Docs AS t1 WITH(NOLOCK) ON ( 1 = 1 AND UserData.[tp_RowOrdinal] = 0 AND t1.SiteId =
UserData.tp_SiteId AND t1.SiteId = @L2 AND t1.DirName = UserData.tp_DirName AND t1.LeafName = UserData.tp_LeafName AND t1.Level =
UserData.tp_Level AND t1.IsCurrentVersion = 1 AND (1 = 1)) WHERE UserData.tp_ListID=@L4 AND ( (UserData.tp_IsCurrent = 1) ) AND UserData.tp_SiteId=@L2 AND (UserData.tp_DirName=@DN) AND UserData.tp_RowOrdinal=0 AND ((UserData.[nvarchar3] = @L3TXP) AND t1.SiteId=@L2 AND (t1.DirName=@DN)) ORDER BY UserData.[tp_ID] Asc ) AS t3 LEFT OUTER JOIN UserDataJunctions AS t4 ON t3.[tp_SiteId] = t4.[tp_SiteId] AND t3.[tp_DeleteTransactionId] = t4.[tp_DeleteTransactionId] AND t3.[tp_IsCurrentVersion] = t4.[tp_IsCurrentVersion] AND t3.[tp_DirName] = t4.[tp_DirName] AND t3.[tp_LeafName] = t4.[tp_LeafName] AND t3.[tp_CalculatedVersion] = t4.[tp_CalculatedVersion] AND t3.[tp_Level] = t4.[tp_Level] LEFT OUTER JOIN UserDataJunctions AS t2 ON t3.[tp_SiteId] = t2.[tp_SiteId] AND t3.[tp_DeleteTransactionId] = t2.[tp_DeleteTransactionId] AND t3.[tp_IsCurrentVersion] = t2.[tp_IsCurrentVersion] AND t3.[tp_DirName] = t2.[tp_DirName] AND t3.[tp_LeafName] = t2.[tp_LeafName] AND t3.[tp_CalculatedVersion] = t2.[tp_CalculatedVersion] AND t3.[tp_Level] = t2.[tp_Level] AND t4.[tp_Ordinal] = t2.[tp_Ordinal] AND t2.[tp_FieldId] = ''{91b18af0-5ef3-477b-aec1-94ab1f7ddd80}'' LEFT OUTER JOIN AllUserData AS t8 WITH(NOLOCK, INDEX=AllUserData_PK) ON (t8.[tp_ListId] = @L5 AND t8.[tp_Id] = t2.[tp_ID] AND t8.[tp_RowOrdinal] = 0 AND t8.[tp_CalculatedVersion] = 0 AND t8.[tp_DeleteTransactionId] = 0x ) ) AS t5 LEFT OUTER JOIN Docs AS t7 WITH(NOLOCK) ON t7.[SiteId] = t5.[tp_SiteId] AND t7.[DeleteTransactionId] = t5.[tp_DeleteTransactionId] AND t7.[DirName] = t5.[tp_DirName] AND t7.[LeafName] = t5.[tp_LeafName] AND t7.[Level] = t5.[tp_Level] ORDER BY t5.tp_ID Asc,t5.[tp_Ordinal] OPTION (FORCE ORDER) ',N'@L0 uniqueidentifier,@L2 uniqueidentifier,@L3TXP nvarchar(255),@DN nvarchar(260),@L4 uniqueidentifier,@L5 uniqueidentifier',@L0='00000000-0000-0000-0000-000000000000',@L2='CC8A9551-7819-4148-B73D-9DBA0A472335',@L3TXP=N'Product1',@DN=N'/Lists/Products',@L4='60D40990-B719-443F-9CFD-7511BCE6B0D5',@L5='EFF07396-C855-4D93-BBFE-2334B7A3CF68'
The results of three SQL queries:

We only have two view fields but 24 columns are returned. Also we can see that multiple rows returned for same list item are the multi-lookup result set. That’s the way SharePoint deals with multi-lookup value, and tp_Ordinal column identifies different mulitp-lookup value joined with another list. For example, product2's AvailableProvinces column has value of “ON, QC”, the corresponding SQL query returns two rows of data; product3 includes all provinces thus 13 rows are returned from content database.
So data size of SQL server's return won’t become bigger with more versions, but it will grow if more multi-lookup values are added.





